Document updated on May 25, 2023
gRPC backend client
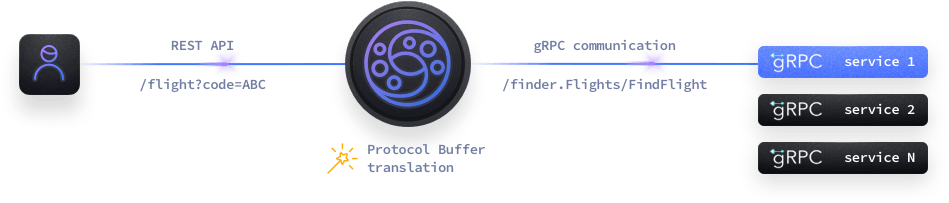
Consuming content from a gRPC upstream service becomes straightforward through KrakenD and hides all the complexity to consumers.
gRPC is a protocol that creates a channel connection between a client and a server and allows calling methods to send and receive payloads serialized with protocol buffers. With the gRPC integration, KrakenD acts as the gRPC client.
KrakenD supports Unary RPCs requests as a backend but not streaming connections (server, client, or bidirectional streaming), as we don’t see fit in the context of an API Gateway.
How gRPC works
You start by creating a list of directories or files containing the protocol buffer definitions and reuse these in each of the backends you want to enable gRPC communication.
The protocol buffer definitions contain the available services, their exposed endpoints and the input and output messages. These definitions are written in .proto files that are used to generate client and server code in different languages using the Protocol Buffer Compiler.
Both proto2 and proto3 are supported.
KrakenD does not directly use .proto files but its binary counterpart: the .pb files. You can generate the binary .pb files with a one-liner using the same Protocol Buffer Compiler you are using today (see below).
gRPC configuration
To add gRPC, you must declare two extra configuration entries in the settings:
grpc: The catalog with all the protocol buffer definitions, at the service level.backend/grpc: The connection to the specific gRPC services in the catalog at the backend level.
For example:
{
"version": 3,
"extra_config": {
"grpc": {
"@comment": "The catalog loads all .pb files passed or contained in directories",
"catalog": [
"grpcatalog/flights/fligths.pb",
"grpcatalog/known_types",
"grpcatalog/third_parties"
]
}
},
"endpoints": [
{
"@comment": "Feature: GRPC",
"endpoint": "/flights",
"input_query_strings": ["*"],
"backend": [
{
"host": ["localhost:4242"],
"url_pattern": "/flight_finder.Flights/FindFlight",
"extra_config": {
"backend/grpc": {}
}
}
]
}
]
}
The configuration of these two entries is as follows.
Catalog definition
You must place the catalog definition at the service level under the grpc extra configuration key, and it requires to contain a list of definitions to load into KrakenD:
Fields of gRPC catalog definition
catalog* array of strings- The paths to the different
.pbfiles you want to load, or the paths to directories containing.pbfiles. All content is scanned in the order of the list, and after fetching all files it resolves the dependencies of their imports. The order you use here is not important to resolve imports, but it matters when there are conflicts (different files using the same namespace and package type).Examples:"./grpc/flights.pb","./grpc/definitions","/etc/krakend/grpc"
While loading the catalog, if there are conflicts, the log will show messages with a WARNING log level.
Backend gRPC call
In the backend level, the inclusion of the backend/grpc object with no content is enough, although there are more optional settings you can add, both for the TLS connection with the gRPC service and how to treat the input parameters or backend response:
Fields of gRPC backend connection
client_tls- Enables specific TLS connection options when using the gRPC service. Supports all options under TLS client settings.
disable_query_paramsboolean- When
true, it does not use URL parameters ({placeholders}in endpoints) or query strings to fill the gRPC payload to send. Ifuse_request_bodyis not set, or set tofalse, and this option is set totrue, there will be no input used for the gRPC message to send. That is still a valid option, when we just want to send the message with its default values, or when the input for the gRPC calls is just the empty message.Defaults tofalse input_mappingobject- A dictionary that converts query string parameters and parameters from
{placeholders}into a different field during the backend request. When passing parameters using{placeholder}the parameter capitalizes the first letter, so you receivePlaceholder.Example:{"lat":"where.latitude","lon":"where.longitude"} output_duration_as_stringboolean- Well-known Duration types (
google.protobuf.Duration) are returned as a struct containing fields withsecondsandnanosfields (flag set tofalse). Setting this flag totruetransforms the timestamps into a string representation in seconds.Defaults tofalse output_enum_as_stringboolean- Enum types are returned as numeric values (flag set to
false). Set this flag totrueto return the string representation of the enum value. For instance, an enum representing allergies, such as['NUTS', 'MILK', ' SOY', 'WHEAT']would return a valueSOYwhen this flag istrue, or2whenfalse.Defaults tofalse output_remove_unset_valuesboolean- When the response has missing fields from the definition, they are returned with default values. Setting this flag to
trueremoves those fields from the response, while setting it tofalseor not setting it, returns all the fields in the definition.Defaults tofalse output_timestamp_as_stringboolean- Well-known Timestamp types (
google.protobuf.Timestamp) are returned as a struct containing fields withsecondsandnanosfields (flag set tofalse). Setting this flag totruetransforms the timestamps into a string representation in RFC3999 format.Defaults tofalse request_naming_convention- Defines the naming convention used to format the request. Applies to query strings and JSON field names. By default, the gateway uses
snake_casewhich makes use of the standardencoding/jsonpackage, while when you choosecamelCasetheprotobuf/encodingdeserialization is used instead.Possible values are:"camelCase","snake_case"Defaults to"snake_case" response_naming_convention- Defines the naming convention used to format the returned data. By default, the gateway uses
snake_casewhich makes use of the standardencoding/jsonpackage, while when you choosecamelCasetheprotobuf/encodingdeserialization is used instead.Possible values are:"camelCase","snake_case"Defaults to"snake_case" use_request_bodyboolean- Enables the use of the sent body to fill the gRPC request. Take into account that when you set this flag to
truea body is expected, and this body is consumed in the first backend. If the endpoint that uses this gRPC backend has additional backends (either gRPC or HTTP) that also expect to consume the payload, these requests might fail.Defaults tofalse
A few important requirements you should have in mind when adding backend configurations:
hostThe array of hosts does not have a protocol prefix (nohttporhttps, justhost:port).url_pattern: Cannot contain variables and must be the full name of the gRPC service and method call (for example:"/pizzeria_sample.Pizzeria/ListMenu")
Ignored attributes (their values or presence is ignored):
methodis_collection
In regards to the endpoint configuration, the output_encoding you set in the endpoint must be different than no-op.
The backend reponse after the gRPC interaction accepts all the manipulation options as it happens with REST calls.
For instance:
{
"@comment": "Feature: GRPC",
"endpoint": "/flights",
"input_query_strings": ["*"],
"backend": [
{
"host": ["localhost:4242"],
"url_pattern": "/flight_finder.Flights/FindFlight",
"extra_config": {
"backend/grpc": {
"client_tls": {
"@comment": "Allow untrusted certificates in development stage",
"allow_insecure_connections": true
}
}
}
}
]
}
Passing user parameters
To pass dynamic parameters from the user to your gRPC service, you must do it using query strings, a body, or using {placeholders} in the endpoints.
When you use query strings, you must always include the necessary input_query_strings, or you can even pass all the query strings with a wildcard * because only those that match the gRPC call will pass.
When you use a {placeholder} in the URL of the endpoint, the variable name capitalizes the fist letter. For a variable {foo} you must refer to it as Foo.
For instance:
{
"@comment": "Feature: GRPC",
"endpoint": "/flights/{date}",
"input_query_strings": ["*"],
"backend": [
{
"host": ["localhost:4242"],
"url_pattern": "/flight_finder.Flights/FindFlight",
"extra_config": {
"backend/grpc": {
"client_tls": {
"@comment": "Allow untrusted certificates in development stage",
"allow_insecure_connections": true
}
}
}
}
]
}
In addition, you can map the original input query string parameters to other keys using the input_mapping property.
For instance, the following example takes a request with ?lat=123&lon=456 and sends a request to the gRPC service with a renamed object. The Date (notice the first letter is uppercased) is taken from the URL, while the coordinates are taken from the query string:
{
"@comment": "Feature: GRPC",
"endpoint": "/flights/{date}",
"input_query_strings": ["*"],
"backend": [
{
"host": ["localhost:4242"],
"url_pattern": "/flight_finder.Flights/FindFlight",
"extra_config": {
"backend/grpc": {
"input_mapping": {
"lat": "where.latitude",
"lon": "where.longitude",
"Date": "when.departure"
}
}
}
}
]
}
The gRPC service receives:
{
"where": {
"latitude": 123,
"longitude": 456
},
"when": {
"departure": "2023-07-09"
}
}
In addition to query parameters, you can pass a body through the flag use_request_body. When both the params/query strings and the body input are enabled, the parameters and query string are set first, and the JSON body secondly. This means that the body will overwrite colliding values set by the params/query strings (you pass the same fields in both). Or said otherwise: params / query values will only apply when those values are not set in the body payload.
Limitations
For child messages (or child objects), the input params are expected
to be in dot notation, e.g., some_field.child.grand_child=10.
It accepts lists (“repeated” in gRPC nomenclature) of basic types with
repeated notation: a=1&a=2&a=3
Or also when the array is inside an object, e.g., a.b.c=1&a.b.c=2&a.b.c=3
But it cannot fill arrays that contain other arrays, or arrays that contain other objects (that could include other arrays) because is difficult to know where a value should be put.
For example, for an object
{
"a": {
"b": [
{
"x": [1, 2]
},
{
"x": [5, 6]
}
],
"c": "something"
}
}
What should be the output for a.b.x=1&a.b.x=2?
Should it be: {"a": {"b": [{"x": [1, 2]}]}} or {"a": {"b": [{"x": [1]}, {"x": [2]}]}}?
Generating binary protocol buffer files (.pb)
You can create .pb files with a command like the one below:
protoc --descriptor_set_out=file.pb file.proto
Nevertheless, you can use two different approaches to provide the necessary .pb information:
- Create multiple
.pbfiles, one for each.protofile you have - Gather all
.protofiles and create a single.pbfile that contains all the definitions.
Multiple .pb files example
This script assumes that you execute it from the root directory where you have all the .proto files you want to collect and places the .pb files under a ../defs directory.
#!/bin/bash
DSTDIR='../defs'
for pfile in $(find . -name '*.proto')
do
reldir=$(echo $(dirname $pfile) | sed "s,^\.,$DSTDIR,g")
mkdir -p $reldir
fname=$(basename $pfile)
fname=$(echo "${reldir}/${fname%.proto}.pb")
protoc --descriptor_set_out=$fname $pfile
done
A single .pb file
If you have all your .proto files under the same directory, it is easy to create a single .pb file that contains all the definitions:
mkdir -p ./defs
cd contracts && \
protoc \
--descriptor_set_out=../fullcatalog.pb \
$$(find . -name '*.proto')
Handling dependencies
KrakenD needs to know about each of the services you want to call and their dependencies. If you import other definitions in your .proto files, it will also need the .pb file for those imported types.
For example, if you have a code like this:
syntax = "proto3";
import "mylib/protobuf/something.proto";
As you import another .proto, you must have the something.pb binary definition to send or receive that data. Missing definitions will result in data not being filled (it will not fail, but the data will not be there).
KrakenD emits warning logs for missing message type definitions.
Well-known types
In the official Protocol Buffers repository, under src/google/protobuf folder, you can find some common message definitions, like timestamp.proto or duration.proto.
If you include those types in your message definitions, you might want to collect those to create their binary .pb counterparts to be used by KrakenD.
This is an example of how to get the .proto files for those “well known types” from the protoc GitHub repo, assuming you have ./contracts dir, where you want to store the files (that can be the same place where you store your own .proto files):
mkdir -p ./tmp && \
cd ./tmp && \
git clone --depth=1 https://github.com/protocolbuffers/protobuf.git
mv ./tmp/protobuf/src/google ./contracts
rm -rf ./contracts/google/protobuf/compiler
find ./contracts/google -type f | grep -v '\.proto' | xargs rm
find ./contracts/google -type f | grep 'unittest' | xargs rm
find ./contracts/google -type d -empty -delete
rm -rf ./tmp
As you can see in the script above, we get rid of all unittest proto definitions.
It is advised to create your script to collect from different directories or repositories.
KrakenD internally transforms some well-known types to its JSON representation:
timestamp.protoduration.proto
Being the timestamp the most frequently used across all applications. For the rest of the well-known types the structure remains in the response as it is defined in the protobuf file. E.g., an Any type is returned as an URL and a bytes field, but it does not resolve to a new message.
