Document updated on May 25, 2023
gRPC client and gRPC to REST conversion
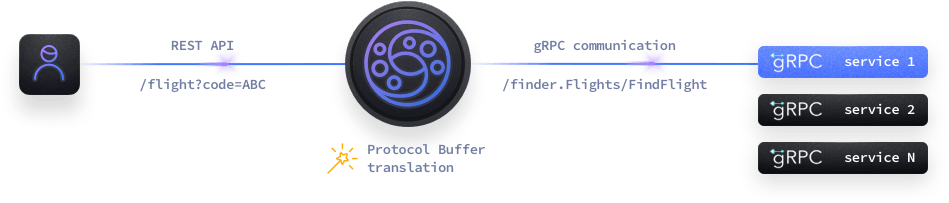
The gRPC client integration allows KrakenD to connect to upstream services using gRPC. If you haven’t enabled the gRPC server functionality, then the content is automatically transformed to a regular REST API, as shown in the picture.
If, on the other hand, you enable a gRPC server, then you can have a gRPC-to-gRPC communication.
gRPC client configuration
To use the gRPC client, you must declare two extra configuration entries in the settings:
grpc: The catalog with all the protocol buffer definitions, at the service level. See the catalog definition.backend/grpc: This is the connection to the specific gRPC services in the catalog at the backend level.
For example:
{
"version": 3,
"extra_config": {
"grpc": {
"@comment": "The catalog loads all .pb files passed or contained in directories",
"catalog": [
"grpcatalog/flights/fligths.pb",
"grpcatalog/known_types",
"grpcatalog/third_parties"
]
}
},
"endpoints": [
{
"@comment": "Feature: GRPC",
"endpoint": "/flights",
"input_query_strings": ["*"],
"backend": [
{
"host": ["localhost:4242"],
"url_pattern": "/flight_finder.Flights/FindFlight",
"extra_config": {
"backend/grpc": {}
}
}
]
}
]
}
At the backend level, the inclusion of the backend/grpc object with no content is enough, although there are more optional settings you can add, both for the TLS connection with the gRPC service and how to treat the input parameters or backend response:
Fields of gRPC backend connection
client_tls- Enables specific TLS connection options when using the gRPC service. Supports all options under TLS client settings.
disable_query_paramsboolean- When
true, it does not use URL parameters ({placeholders}in endpoints) or query strings to fill the gRPC payload to send. Ifuse_request_bodyis not set, or set tofalse, and this option is set totrue, there will be no input used for the gRPC message to send. That is still a valid option, when we just want to send the message with its default values, or when the input for the gRPC calls is just the empty message.Defaults tofalse header_mappingobject- A dictionary that rename the received header (key) to a new header name (value). If the header starts with
grpcthey will be renamed toin-grpc-*as the word is reserved.Example:{"X-Tenant":"customerid"}Properties of
header_mappingcan use a name matching the pattern.*, and their content is anstring idle_conn_disconnect_timestring- The maximum time a connection is kept without being used.Specify units using
ns(nanoseconds),usorµs(microseconds),ms(milliseconds),s(seconds),m(minutes), orh(hours).Defaults to"10m" input_assume_bytes- When set to true, when the backend has to fill a bytes field for a grpc protobuf payload to send, first tries to decode the input data (the one coming from either a json body field, a query param or header string) from base64: if it succeeds it fills the field to send with that binary / bytes data. If the incoming field is not a valid base64 decoded field (the one used in jsonpb), it will fill the binary field with the verbatim conversion of the incoming string to bytes.Defaults to
false input_mappingobject- A dictionary that converts query string parameters and parameters from
{placeholders}into a different field during the backend request. When passing parameters using{placeholder}the parameter capitalizes the first letter, so you receivePlaceholder.Example:{"lat":"where.latitude","lon":"where.longitude"}Properties of
input_mappingcan use a name matching the pattern.*, and their content is anstring max_call_recv_msg_sizenumber- Specifies the maximum size (in bytes) for messages the grpc client is allowed to receive. If the value is unset, or
0, it uses its default (4MB)Examples:33554432,4194304,0 output_duration_as_stringboolean- Well-known Duration types (
google.protobuf.Duration) are returned as a struct containing fields withsecondsandnanosfields (flag set tofalse). Setting this flag totruetransforms the timestamps into a string representation in seconds.Defaults tofalse output_enum_as_stringboolean- Enum types are returned as numeric values (flag set to
false). Set this flag totrueto return the string representation of the enum value. For instance, an enum representing allergies, such as['NUTS', 'MILK', ' SOY', 'WHEAT']would return a valueSOYwhen this flag istrue, or2whenfalse.Defaults tofalse output_remove_unset_valuesboolean- This attribute defines what to do when a field that is declared in the definition does not exist in the backend response. When the flag is
true, any fields in the definition that are not present in the backend response are removed before returning the content to the user. When the flag isfalsemissing fields are returned but set with a zeroed-value depending on its type (zero, nil, false, etc).Defaults tofalse output_timestamp_as_stringboolean- Well-known Timestamp types (
google.protobuf.Timestamp) are returned as a struct containing fields withsecondsandnanosfields (flag set tofalse). Setting this flag totruetransforms the timestamps into a string representation in RFC3999 format.Defaults tofalse read_buffer_sizenumber- Specifies the size of the client buffer reading the gRPC communication in bytes. If the value is unset, or
0, it uses its default (32KB). Use a negative value to disable the buffer, and if you do there won’t be memory pre-allocation to read. To determine the right number, calculate the average size of the responses the gRPC client will receive.Examples:32768,8192,-1 request_naming_convention- Defines the naming convention used to format the request. Applies to query strings and JSON field names. By default, the gateway uses
snake_casewhich makes use of the standardencoding/jsonpackage, while when you choosecamelCasetheprotobuf/encodingdeserialization is used instead.Possible values are:"camelCase","snake_case"Defaults to"snake_case" response_naming_convention- Defines the naming convention used to format the returned data. By default, the gateway uses
snake_casewhich makes use of the standardencoding/jsonpackage, while when you choosecamelCasetheprotobuf/encodingdeserialization is used instead.Possible values are:"camelCase","snake_case"Defaults to"snake_case" use_alternate_host_on_errorboolean- When
true, before sending a message to a host, it checks if the connection status is in a “transient failure” or “failure” state and tries to use a different host (from the service discovery or randomly from the list of hosts). If the connection is in a valid state, but an error happens when sending the gRPC message, it also tries to use a different host to retry sending the message. Depending on the host list, the retry attempts may go to the same host initially in a “bad state”. use_request_bodyboolean- Enables the use of the sent body to fill the gRPC request. Take into account that when you set this flag to
truea body is expected, and this body is consumed in the first backend. If the endpoint that uses this gRPC backend has additional backends (either gRPC or HTTP) that also expect to consume the payload, these requests might fail.Defaults tofalse
A few important requirements you should have in mind when adding backend configurations:
hostThe array of hosts does not have a protocol prefix (nohttporhttps, justhost:port).url_pattern: Cannot contain variables and must be the full name of the gRPC service and method call (for example:"/pizzeria_sample.Pizzeria/ListMenu")
Ignored attributes (their values or presence is ignored):
methodis_collection
Regarding the endpoint configuration, the output_encoding you set in the endpoint must be different than no-op.
The backend response after the gRPC interaction accepts all the manipulation options as with REST calls.
For instance:
{
"@comment": "Feature: GRPC",
"endpoint": "/flights",
"input_query_strings": ["*"],
"backend": [
{
"host": ["localhost:4242"],
"url_pattern": "/flight_finder.Flights/FindFlight",
"extra_config": {
"backend/grpc": {
"client_tls": {
"@comment": "Allow untrusted certificates in development stage",
"allow_insecure_connections": true
}
}
}
}
]
}
Passing user parameters
To pass dynamic parameters from the user to your gRPC service, you must use query strings, a body, headers (sent as metadata), or {placeholders} in the endpoints.
When you use query strings, you must always include the necessary input_query_strings. You can even pass all the query strings with a wildcard * because only those that match the gRPC call will pass.
Headers must be listed in the endpoint’s input_headers array when you use them. In addition, the field header_mapping under the backend/grpc section allows you to rename those headers to gRPC metadata. All headers in the gRPC backend will be sent with their original (but lowercased) name or using the provided header_mapping.
When you use a {placeholder} in the URL of the endpoint, the variable name capitalizes the first letter. You must refer to a variable {foo} as Foo.
For instance:
{
"@comment": "Feature: GRPC",
"endpoint": "/flights/{date}",
"input_query_strings": ["*"],
"input_headers": ["*"],
"backend": [
{
"host": ["localhost:4242"],
"url_pattern": "/flight_finder.Flights/FindFlight",
"extra_config": {
"backend/grpc": {
"header_mapping": {
"X-Tenant": "customerid"
},
"client_tls": {
"@comment": "Allow untrusted certificates in development stage",
"allow_insecure_connections": true
}
}
}
}
]
}
In addition, you can map the original input query string parameters to other keys using the input_mapping property.
For instance, the following example takes a request with ?lat=123&lon=456 and sends a request to the gRPC service with a renamed object. The Date (notice the first letter is uppercased) is taken from the URL, while the coordinates are taken from the query string:
{
"@comment": "Feature: GRPC",
"endpoint": "/flights/{date}",
"input_query_strings": ["*"],
"backend": [
{
"host": ["localhost:4242"],
"url_pattern": "/flight_finder.Flights/FindFlight",
"extra_config": {
"backend/grpc": {
"input_mapping": {
"lat": "where.latitude",
"lon": "where.longitude",
"Date": "when.departure"
}
}
}
}
]
}
The gRPC service receives:
{
"where": {
"latitude": 123,
"longitude": 456
},
"when": {
"departure": "2023-07-09"
}
}
In addition to query parameters, you can pass a body through the flag use_request_body. When both the params/query strings and the body input are enabled, the parameters and query string are set first and the JSON body second. This means the body will overwrite colliding values set by the params/query strings (you pass the same fields in both). Or said otherwise: params/query values will only apply when those values are not set in the body payload.
Finally, fields for the GRPC body can also be taken from the headers data (but query string values and URL parameters take precedence if provided over the values found in the headers).
Passing well-known types
When one of the inputs for a well known type of Timestamp or Duration is a string instead of fields for the object (like seconds and nanoseconds for a Timestamp), if valid, we can interpret the string as a RFC3339 time value for Timestamp, or a duration string.
Limitations
For child messages (or child objects), the input params are expected
to be in dot notation, e.g., some_field.child.grand_child=10.
It accepts lists (“repeated” in gRPC nomenclature) of basic types with
repeated notation: a=1&a=2&a=3
Or also when the array is inside an object, e.g., a.b.c=1&a.b.c=2&a.b.c=3
But it cannot fill arrays that contain other arrays or arrays that contain other objects (that could include other arrays) because it is difficult to know where a value should be put.
For example, for an object
{
"a": {
"b": [
{
"x": [1, 2]
},
{
"x": [5, 6]
}
],
"c": "something"
}
}
What should be the output for a.b.x=1&a.b.x=2?
Should it be: {"a": {"b": [{"x": [1, 2]}]}} or {"a": {"b": [{"x": [1]}, {"x": [2]}]}}?
