Document updated on Oct 20, 2018
Concurrent Requests
The concurrent requests are an excellent technique to improve the response times and decrease error rates by requesting in parallel the same information multiple times. When the first backend returns the information, the remaining threads are canceled.
It depends a lot on your configuration, but improving response times by a 75% or more with the same application you are using today is not something rare.
When using concurrent requests, the backend services must be able to handle an additional load. If this is the case, and your requests are idempotent, then you can use concurrent_calls as follows:
...,
"endpoints": [
{
"endpoint": "/products",
"method": "GET",
"concurrent_calls": 3,
"backend": [
{
"host": [
"http://server-01.api.com:8000",
"http://server-02.api.com:8000"
],
"url_pattern": "/foo",
...
In the example above, when a user calls the /products endpoint, KrakenD opens three different connections to the backends and returns the first fastest successful response.
Notice that despite this backend has only two servers to handle the load, the concurrent_calls is set to three. The two settings are not related, and KrakenD is going to open three connections against these two servers nevertheless. Which server receives 1,2 or all three depends on the internal load balancer decision.
What is the ideal number for concurrent_calls?
There isn’t a recommended number, as this ultimately depends on how your services behave and the number of resources you have for every service.
Nevertheless, we could say that if you are interested in this feature, 3 is a good number, as it offers superior results without needing to double your resources.
Generally speaking, if you work on the cloud, enabling this feature is safer as you can grow the resources easily (but put an eye on the costs). If your hardware is limited (on-premise), do not activate this feature in production without doing your proper load tests.
How does concurrent_calls work?
KrakenD sends up to N concurrent_calls to your backends for the **same request to an endpoint. When the first successful response is received, KrakenD cancels the remaining requests and ignores any previous failures. Only in the case that all concurrent_calls fail, the endpoint receives the failure as well.
The apparent trade-off of this strategy is the increment of the load in the backend services, so make sure your infrastructure is ready for it. However, your users love it: Fewer errors and faster responses!
Impact of concurrent requests
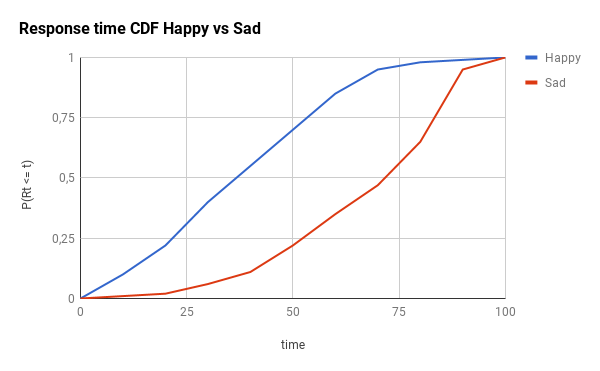
To demonstrate the impact of this component, let’s imagine two different scenarios: the happy one and the sad one. Here you have the CDF (cumulative distribution) and the PDF (probability distribution) of these two cases (the time range is just a placeholder for whatever your actual response time values are, replace the 100 with your max_response_time):
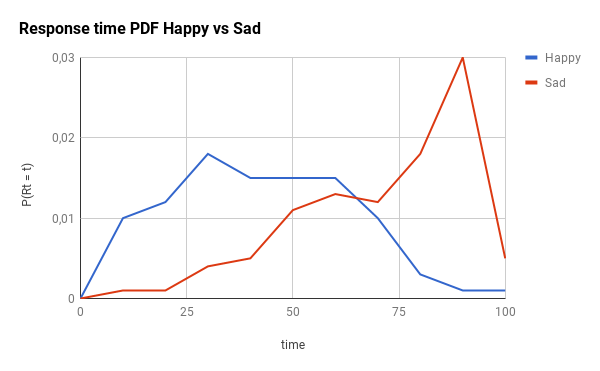
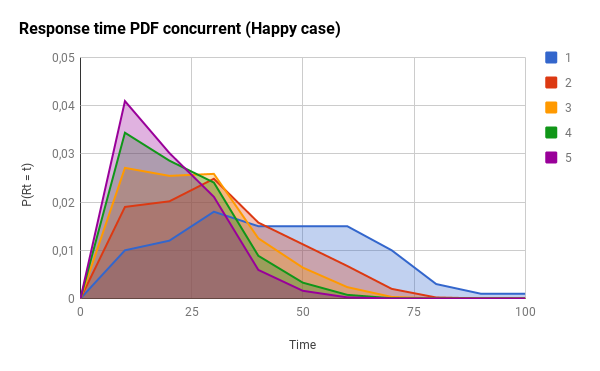
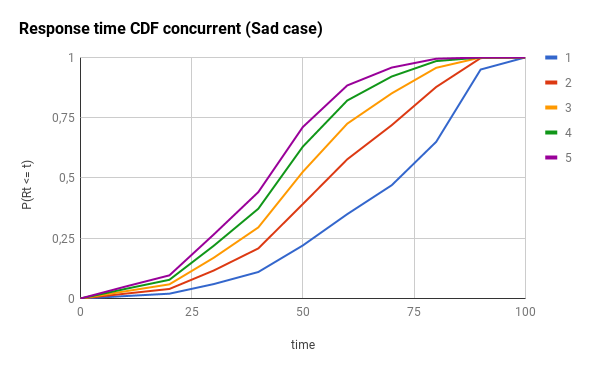
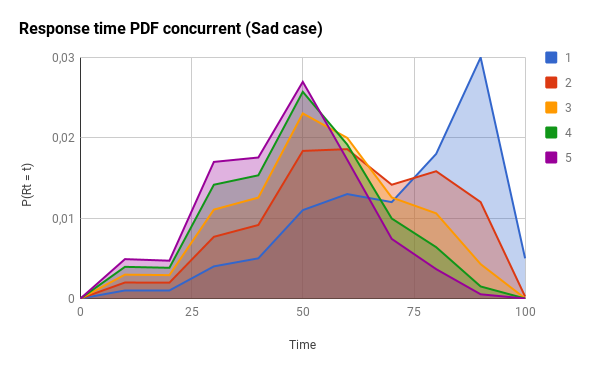
Just as a reminder: for the CDF graphs, the more to the left the line is, the better. For the PDF graphs, the more to the left and the narrow the peak is, the better.
The following graph is the effect of using different concurrency levels for the happy case (notice how the response times concentrate around 20% of the max_response_time):
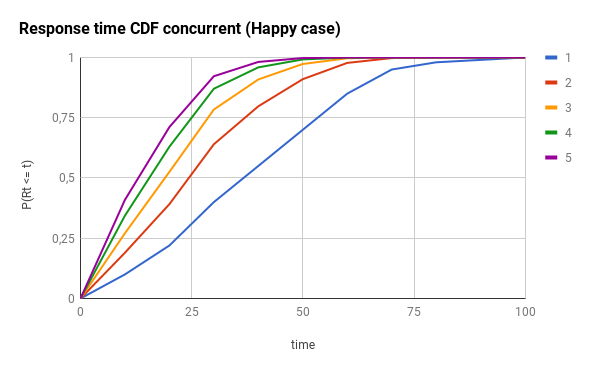
Here, you have the effects for the sad case:
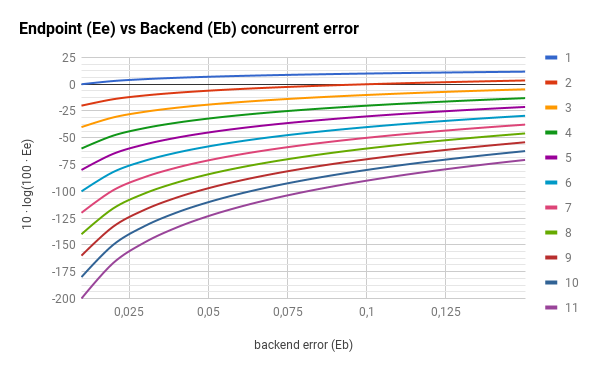
The concurrent request component also reduces the error rate of the exposed endpoint by orders of magnitude.
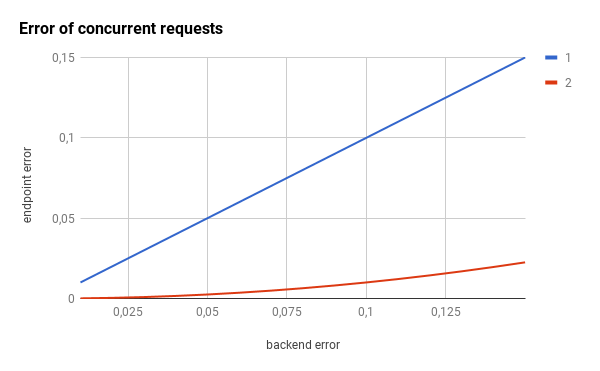
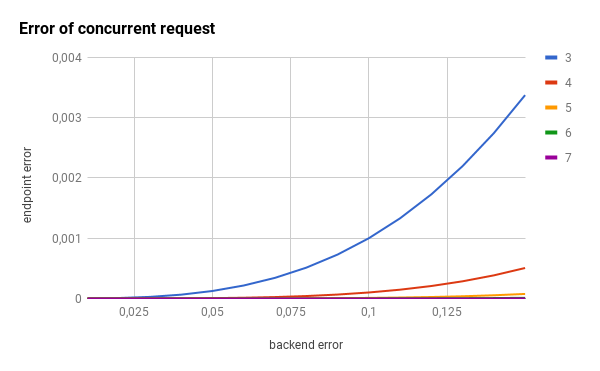
Since the scale of the previous graphs is hiding the huge impact, let’s use a logarithmic scale: