Document updated on Jan 16, 2024
GraphQL Backend Integration
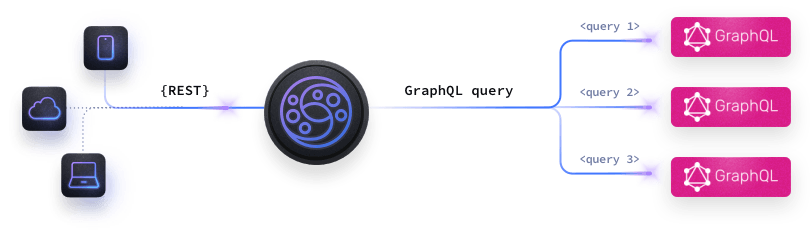
The GraphQL integration allows you to work in two different modes:
- Apply gateway functionality in the middle of a GraphQL client and its GraphQL servers (just proxy)
- Convert REST endpoints to GraphQL calls (adapter/transformer).
KrakenD offers a simple yet powerful way of consuming GraphQL content from your distributed graphs. The main benefits of using KrakenD as a GraphQL Gateway are:
- Simple GraphQL Federation: chop your monolithic GraphQL server into different services and aggregate them in the gateway.
- User validation: Handle the authorization in the gateway before adding any load to your GraphQL servers.
- Protect and secure internal GraphQL endpoints
- Rate limit GraphQL usage
- Prepare aggregated data for external caching
- Hide complexity to the clients by providing a REST interface
REST to GraphQL transformation
In this scenario, the end-user consumes traditional REST content, without even knowing that there is a GraphQL server behind:
KrakenD can use the variables in the body or in the endpoint URL to generate the final GraphQL query it will send to the GraphQL server. The query is loaded from an external file or declared inline in the configuration and contains any variables needing replacement with the user input.
KrakenD acts as the GraphQL client, negotiating the content with the GraphQL server and hiding its complexity from the end-user. The end-user consumes REST content and retrieves the data in JSON, XML, RSS, or any other format supported by KrakenD.
The configuration to consume GraphQL content from your GraphQL graphs could look like this:
{
"endpoint": "/marketing/{user_id}",
"method": "POST",
"backend": [
{
"timeout": "4100ms",
"url_pattern": "/graphql?timeout=4s",
"extra_config": {
"backend/graphql": {
"type": "mutation",
"query_path": "./graphql/mutations/marketing.graphql",
"variables": {
"user":"{user_id}",
"other_static_variables": {
"foo": false,
"bar": true
}
},
"operationName": "addMktPreferencesForUser"
}
}
}
]
}The configuration for the namespace backend/graphql has the following structure:
Fields of GraphQL
Minimum configuration needs one of:
type
+
query
, or
type
+
query_path
operationNamestring- A meaningful and explicit name for your operation, required in multi-operation documents and for helpful debugging and server-side logging.Example:
"addMktPreferencesForUser" querystring- An inline GraphQL query you want to send to the server. Use this attribute for simple and inline queries, use
query_pathinstead for larger queries. Use escaping when needed.Example:"{ \n find_follower(func: uid(\"0x3\")) {\n name \n }\n }" query_pathstring- Path to the file containing the query. This file is loaded during startup and never checked again, if it changes KrakenD will be unaware of it.Example:
"./graphql/mutations/marketing.graphql" type- The type of query you are declaring,
query(read), ormutation(write).Possible values are:"query","mutation" variablesobject- A dictionary defining all the variables sent to the GraphQL server. You can use
{placeholders}to inject parameters from the endpoint URL.
When using an inline query (instead of a file from the query_path, which does this job automatically), use escape when needed. Examples:
- "query": "{ \n find_follower(func: uid(\"0x3\")) {\n name \n }\n }".
- "query": "{ q(func: uid(1)) { uid } }"
The combination of type and the endpoint/backend method define how you accept parameters from the users and how you send the query to the server, respectively:
- A type
querymeans you accept user parameters in the query string. - A type
mutationmeans you accept user parameters in the body. - A method
GETsends the query to the GraphQL server as an autogenerated query string. - A method
POSTsends the query to the GraphQL server as an autogenerated body. When the user and the KrakenD configuration define the same variables (collision), the user variables take preference.
In all, the following combinations are possible:
method=GET+type=query: Generates a query string using any{variables}in the endpoint, but you don’t have any data in a possible body.method=GET+type=mutation: Generates a query string including any variables in the body of the REST call (if present), but you cannot have{variables}from the URLmethod=POST+type=query: Generates a body using any{variables}in the endpoint, but it does not use the user’s body to form the new body.method=POST+type=mutation: Generates a body including any variables in the REST body plus the ones in the configuration, but you cannot have{variables}from the URL
application/json, and is not longer needed to pass it from the client.Examples of GraphQL request generation
POST + mutation
Suppose the end-user makes the following request to KrakenD, which contains a body with a JSON containing review information to /review/{id_show}:
Query to graphql endpoint
$curl -XPOST -d '{ "review": { "stars": 5, "commentary": "This is a great movie!" } }' http://krakend/review/1500The mutation is stored in an external file called review.graphql and has the following content:
mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) {
createReview(episode: $ep, review: $review) {
stars
commentary
}
}
The configuration of KrakenD for this example is as follows:
{
"endpoint": "/review/{id_show}",
"method": "POST",
"backend": [
{
"timeout": "4100ms",
"url_pattern": "/graphql?timeout=4s",
"extra_config": {
"backend/graphql": {
"type": "mutation",
"query_path": "./graphql/mutations/review.graphql",
"variables": {
"review": {
"stars": 3,
"commentary": "meh"
},
"ep": "JEDI",
"id_show": "{id_show}"
},
"operationName": "CreateReviewForEpisode"
}
}
}
]
}
With the example and the configuration of KrakenD above, when the user sends a body, it will be sent to the backend as it is. However, if the user does not include any of the variables in the body, it will add them to the final request to the backend. So, with this example, any review will receive 3 stars and a “meh” comment if the end-user does not pass it.
With the cURL request in the example above, the backend receives the following JSON payload:
{
"query": "mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) {\ncreateReview episode: $ep, review: $review) {\nstars\ncommentary\n}\n}\n",
"variables": {
"ep": "JEDI",
"review": {
"stars": 5,
"commentary": "This is a great movie!"
},
"id_show": "{id_show}"
},
"operationName": "CreateReviewForEpisode"
}
- The
querycontains the content of the external file defining the GraphQL you want to execute. - The
variablessection contains the following:- The variable
id_showdoes not replace the value of{id_show}, as it is a POST + mutation - The
epfield is passed as it is in the configuration because the user did not pass it. - The
reviewvariable is used because the POST has data and is included in the final body, which is also passed to the GraphQL server.
- The variable
GET + mutation
In case the method is a GET instead of a body. The configuration we will use is as follows:
{
"endpoint": "/review/{stars}",
"method": "GET",
"backend": [
{
"timeout": "4100ms",
"url_pattern": "/graphql?timeout=4s",
"extra_config": {
"backend/graphql": {
"type": "mutation",
"query_path": "./graphql/mutations/review.graphql",
"variables": {
"review": {
"stars": "{stars}"
},
"ep": "JEDI",
"id_show": "1500"
},
"operationName": "CreateReviewForEpisode"
}
}
}
]
}
And we call the endpoint like this (notice that because this is a mutation, we must pass a body):
Query to graphql endpoint
$curl -d '' -G http://krakend/review/5In this case, the GraphQL server receives a URL-encoded query with all the variables, where:
- The variable
{stars}is replaced by its value5as passed in the URL - The
review, andepfields are passed as they are in the configuration.
POST + Query
In this example, we want to do a query instead of a mutation, and we have a query_path file with the following content:
query Hero($episode: Episode, $withFriends: Boolean!) {
hero(episode: $episode) {
name
friends @include(if: $withFriends) {
name
}
}
}
And a KrakenD configuration like this:
{
"endpoint": "/hero/{episode}",
"method": "POST",
"backend": [
{
"timeout": "4100ms",
"url_pattern": "/graphql?timeout=4s",
"extra_config": {
"backend/graphql": {
"type": "query",
"query_path": "./graphql/mutations/hero.graphql",
"variables": {
"episode": "{episode}",
"withFriends": false
},
"operationName": "Hero"
}
}
}
]
}
Query to graphql endpoint
$curl -XPOST http://krakend/hero/JEDIThe GraphQL receives a body with the following content:
{
"query": "query Hero($episode: Episode, $withFriends: Boolean!) {\n hero(episode: $episode) {\n name\n friends @include(if: $withFriends) {\n name\n }\n }\n}",
"variables": {
"episode": "JEDI",
"withFriends": false
},
"operationName": "Hero"
}
As you can see, even though this is a POST, the body is ignored.
- The
episodevariable is taken from the endpoint parameter, as defined in the configuration - The
withFriendsvariable is hardcoded in the configuration.
GET + Query
The final example of GET + query.
We have the following query in the query_path contents:
query Hero($episode: Episode, $withFriends: Boolean!) {
hero(episode: $episode) {
name
friends @include(if: $withFriends) {
name
}
}
}
On KrakenD configuration:
{
"endpoint": "/hero/{episode}",
"method": "GET",
"backend": [
{
"timeout": "4100ms",
"url_pattern": "/graphql?timeout=4s",
"extra_config": {
"backend/graphql": {
"type": "query",
"query_path": "./graphql/mutations/hero.graphql",
"variables": {
"episode": "{episode}",
"withFriends": false
},
"operationName": "Hero"
}
}
}
]
}
Query to graphql endpoint
$curl -XGET http://krakend/hero/JEDIIn this case, the GraphQL server receives a URL-encoded query with all the variables, where:
- The variable
{episode}is replaced by its valueJEDI - The
withFriendsfield is passed as it is in the configuration.
GraphQL gateway as a proxy
In this approach, KrakenD gets in the middle to validate or rate limit requests, but the request is forwarded to the GraphQL servers, who receive the original GraphQL query from the end user.

When working in this mode, you only need to configure the GraphQL endpoint and add your GraphQL as the backend. An example:
{
"endpoint": "/graphql",
"method": "POST",
"input_query_strings":[
"query",
"operationName",
"variables"
],
"backend": [
{
"timeout": "4100ms",
"host": ["http://your-graphql.server:4000"],
"url_pattern": "/graphql?timeout=4s"
}
]
}
The previous example uses a set of recognized query strings to pass to the GraphQL server. You can also use "input_query_strings":["*"] to forward any query string. The exact configuration works with a POST method.
As the configuration above does not use `no-op, ’ you can take the opportunity to connect to more servers in the same endpoint by adding additional backend objects in the configuration.
In addition, if you’d like to use your GraphQL from a browser like Apollo Studio, you will need to add two additional components to your configuration:
- Accept the
OPTIONSmethod, adding the flagauto_options - Add CORS
GraphQL Federation
KrakenD’s principles are working with simultaneous aggregation of data. In that sense, consuming multiple subgraphs (or back-end services) comes naturally. However, using the REST to GraphQL capabilities, you can federate data using a simple strategy: define the subgraphs in the configuration instead of moving this responsibility to the consumer.
It is a simplistic but still potent approach, as you can define templates with queries and let krakend aggregate the responses.
Create rest endpoints with fixed graphs you want to consume in the configuration. Then, in each back-end query (subgraph), you decide what transformation rules to apply, the validation, rate-limiting, etc., and even connect your endpoints with other services like queues.
The following example is a REST endpoint consuming data from 2 different subgraphs in parallel. Of course, you could add here any other KrakenD components you could need:
{
"endpoint": "/user-data/{id_user}",
"backend": [
{
"timeout": "3100ms",
"url_pattern": "/graphql?timeout=3s",
"group": "user",
"method": "GET",
"host": ["http://user-graph:4000"],
"extra_config": {
"backend/graphql": {
"type": "query",
"query_path": "./graphql/queries/user.graphql",
"variables": {
"user":"{user_id}"
},
"operationName": "getUserData"
}
}
},
{
"timeout": "2100ms",
"url_pattern": "/graphql?timeout=2s",
"group": "user_metadata",
"method": "GET",
"host": ["http://metadata:4000"],
"extra_config": {
"backend/graphql": {
"type": "query",
"query_path": "./graphql/queries/user_metadata.graphql",
"variables": {
"user":"{user_id}"
},
"operationName": "getUserMetadata"
}
}
}
]
}
