Document updated on Jan 21, 2022
Event-Driven API Gateway: Async Agents
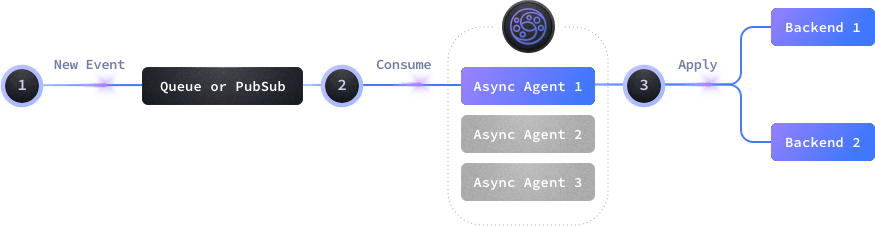
Async agents are routines listening to queues or PubSub systems that react to new events and push data to your backends. Through async agents, you can start a lot of consumers to process your events autonomously.
As opposed to endpoints, async agents do not require users to request something to trigger an action. Instead, the agents connect to an event messaging system and fire an action when an event is delivered.
An async agent can do everything an endpoint can do. You can use plugins, apply transformations and manipulations, scripting, stub data, parallel or sequential calls to multiple backends, jsonschema, OAuth2 client credentials, rate limiting, circuit breaking, validations, lambda, and a long long etcetera.
The obvious limitation is that you cannot use HTTP request functionality (e.g: CORS or JWT validation) as you don’t have any user doing an HTTP request, but an automatic trigger from KrakenD when an event pops in.
When do you need Async Agents
You are trying to implement an event based pattern, such as:
- The Saga Pattern
- Event sourcing
How Async agents work
When KrakenD starts, it reads the async_agent list in the configuration and creates the declared agents. An agent is an application thread that can use one or multiple workers connecting to a queue or PubSub system (consumers). KrakenD contacts the defined backend(s) list passing the event data when a new message kicks in. You might decide to add manipulations, validations, filtering, or any other backend functionality supported by KrakenD.
The backend(s) receive the event from the agent as part of the body. Depending on the driver and configuration, when a backend fails to process the request, you can tell KrakenD to reinject the message (Nack) to retry the message later by any other worker. Notice that when working with Nack, if KrakenD is the only consumer and your backend fails to process the message continuously, KrakenD will reinsert the message into the queue over and over, and could lead to an infinite loop of messages if no consumer empties these messages. To avoid this, set nack_discard to true.
Notice that as it happens with the endpoints, the messages you consume can be sent in parallel or sequentially to multiple services.
Configuration
The async_agent entry is an array with all the different agents you want to have running. Each configuration needs to declare in the extra_config the connection driver you want to use. like this:
{
"version": 3,
"async_agent": [
{
"name": "cool-agent",
"connection": {
"max_retries": 10,
"backoff_strategy":"exponential-jitter",
"health_interval": "10s"
},
"consumer": {
"topic": "*",
"workers": 1,
"timeout": "150ms",
"max_rate": 0.5
},
"backend": [
{
"host": [
"http://127.0.0.1:8080"
],
"url_pattern": "/__debug/"
}
],
"extra_config": {
"async/amqp": {
"host": "amqp://guest:guest@localhost:5672/",
"name": "krakend",
"exchange": "foo",
"durable": true,
"delete": false,
"exclusive": false,
"no_wait": true,
"prefetch_count": 5,
"auto_ack": false,
"no_local": true
}
}
}
]
}
The configuration accepts the following parameters:
Properties of an Async Agent object
backend* array- The backend definition (as you might have in any endpoint) indicating where the event data is sent. It is a full backend object definition, with all its possible options, transformations, filters, validations, etc.
connectionobject- A key defining all the connection settings between the agent and your messaging system.
backoff_strategy- When the connection to your event source gets interrupted for whatever reason, KrakenD keeps trying to reconnect until it succeeds or until it reaches the
max_retries. The backoff strategy defines the delay in seconds in between consecutive failed retries.Possible values are:"linear","linear-jitter","exponential","exponential-jitter","fallback"Defaults to"fallback" health_interval- The time between pings checking that the agent is connected to the queue and alive. Regardless of the health interval, if an agent fails, KrakenD will restart it again immediately as defined by
max_retriesandbackoff_strategy.Specify units usingns(nanoseconds),usorµs(microseconds),ms(milliseconds),s(seconds),m(minutes), orh(hours).Defaults to"1s" max_retriesinteger- The maximum number of times you will allow KrakenD to retry reconnecting to a broken messaging system. Use 0 for unlimited retries.Defaults to
0
consumer*- Defines all the settings for each agent consuming messages.
max_ratenumber- The maximum number of messages you allow each worker to consume per second. Use any of
0or-1for unlimited speed.Defaults to0 timeout- The maximum time the agent will wait to process an event sent to the backend. If the backend fails to process it, the message is reinserted for later consumption. Defaults to the timeout in the root level, or to
2sif no value is declared.Specify units usingns(nanoseconds),usorµs(microseconds),ms(milliseconds),s(seconds),m(minutes), orh(hours). topic* string- The topic name you want to consume. The syntax depends on the driver. Examples for AMQP:
*,mytopic,lazy.#,*,foo.*. workersinteger- The number of workers (consuming processes) you want to start simultaneously for this agent.Defaults to
1
encoding- Informs KrakenD how to parse the responses of your services.Possible values are:
"json","safejson","xml","rss","string","no-op"Defaults to"json" extra_config*- Defines the driver that connects to your queue or PubSub system. In addition, you can place other middlewares to modify the request (message) or the response, apply logic or any other endpoint middleware, but adding the driver is mandatory.* Required one of: (
async/amqp) , or (async/kafka)async/kafka- config details to consume from kafka topics
name* string- A unique name for this agent. KrakenD shows it in the health endpoint and logs and metrics. KrakenD does not check collision names, so make sure each agent has a different name.
Do not forget to set the driver for the Async agent inside the extra_config.
When agents are defined, their activity is shown in the health endpoint with the name of the agent you have chosen. The health endpoint will show for each agent, when was the last time the agent reported itself as alive. The frequency of this checking is as defined in the health_interval.
Check how agents report in the health endpoint
Backoff strategies
The backoff_strategies you can set are defined below:
linear: The delay time (d) grows linearly after each failed retry (r) using the formulad = r. E.g.: 1st failure retries in 1s, 2nd failure in 2s, 3rd in 3s, and so on.linear-jitter: Similar tolinearbut adds or subtracts a random number:d = r ± random. The randomness prevents all agents connected to a mutual service from retrying simultaneously as all have a slightly different delay. The random number never exceeds±r*0.33exponential: Multiplicatively increase the time between retries usingd = 2^r. E.g:2s,4s,8s,16s…exponential-jitter: Same as exponential, but adds or subtracts a random number up to 33% of the value usingd = 2^r ± random. This is the preferred strategy when you want to protect the system you are consuming.- Fallback: When the strategy is missing or none of the above (e.g.:
fallback) then it will use constant backoff strategyd=1. Will retry after one second every time.
